
Hi, I'm Son (ソン) at the CTO office.
One of the projects that I am currently involved in is called Fadil - A Web app for visualizing engineering performance. In the following, I want to explain more about the motivation behind this project, what we are doing, and what's future of this project.
Why we built it?
As Money Forward is growing, there are around ~600 repositories handled by hundreds of engineers, which leads to difficulty in understanding the current performance of engineering in general. We already tried other engineering intelligent tools to track commit history , PR related metrics… However, every company has its own metric to know, these tools just don't meet our requirement. Each business is unique and would require a certain level of customization. Therefore we decided to build our own engineering visualization tool (from scratch).
(Some metrics in our dashboard)

How we built it?
Basically, Fadil aggregates historical data from engineer tools such as Github, CircleCI, Slack….into easy-to-understand insights to help our engineering teams operate more effectively and efficiently. Its a very standard three-tier web application:
- Nuxt.js for frontend.
- Ruby On Rails for backend API.
- AWS Aurora Mysql for the database.
- Terraform for provisioning infrastructure.
- K8S - A standard of the infrastructure of Money Forward (the first version is using AWS Elastic Beanstalk)

Cronjob runs every day at 22:00 to synchronize raw data from ~600 repositories of Github and data from CircleCI, Slack. After that, the server will calculate metrics from these raw data and insert data into the database. That process took around 6 hours to finish. Currently, the biggest table has more than 18 million records. The first version was already released and built-in one month by two enthusiastic interns. :clap:
Lesson learn
Choosing the right metrics, first.
Honestly, we can measure almost anything, but we can't pay attention to everything at the same time. If we attend to all metrics with the same degree of importance, we actually give less attention to them. In fact, the priority of metrics should be related to current business goals. For now, our company is focusing on the speed of delivering products to the market so some metrics such as release count or pull request review time will play a big role. In contrast, some metrics such as the LOC (line of code) that is not important at the moment may have lower priority and will be implemented in the next phase. So the first simple rule:
Focus on metrics that lead to action.
For example, if the release number of a project is going down, we must act quickly to make this metric recover as much as possible.

Don't show number only
Choosing the right metrics is only the first step, the next step is how to make data easy to understand for users. Just displaying the value of metrics at a given time makes it difficult to grasp the moving of metrics. So we decided to build an average metric that shows the trend because building product is a process and we want to know what happens in the last 30 days rather than yesterday.
For example, looking at the number of daily commits as below picture, it is difficult to understand whether the number of commits has increased or decreased recently.
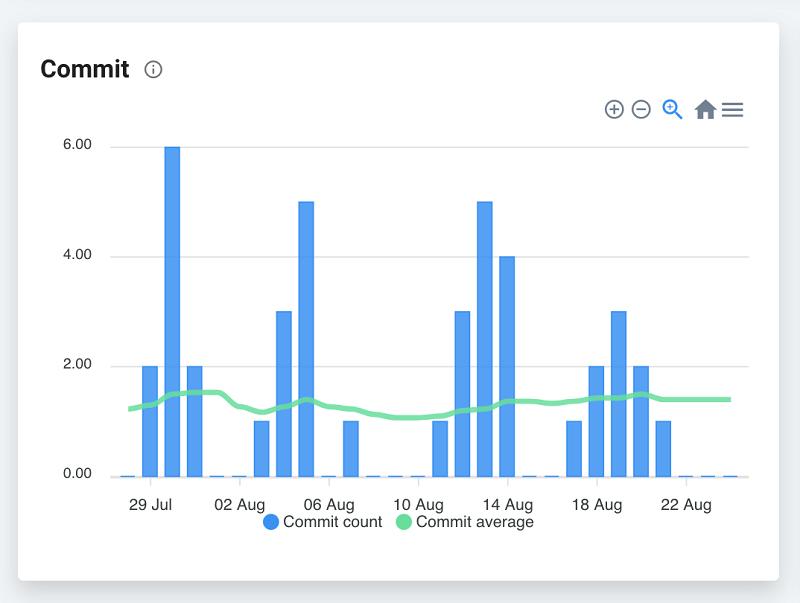
Metrics should be used together
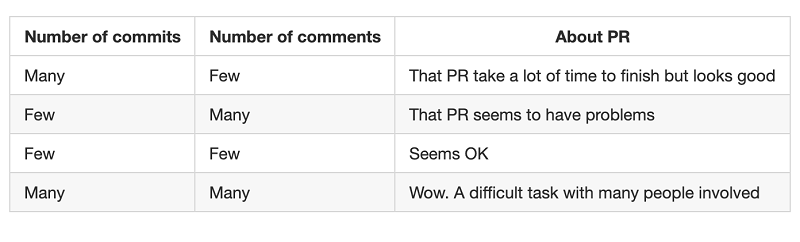
In some cases, a singular metric can hardly provide any insightful information. However with the appropriate combination, it will bring completely new meaning. It can be seen in the case of comments per pull request. If many PRs have small size and always have many comments, there may be a conflict among cooperation or among working styles in the team. But many comments in one big PR could be very understandable because modifying a lot of code could lead to many discussions. (As a leader, it's good to see team member actively cooperate)
Another example, in some repositories, just looking at the review pull request time, it is impossible to judge whether team collaboration is effective due to the decrease in the number of pull requests. (left picture) In the other hand, although the number of pull requests dramatically increase, the review time decreases which means team collaboration is working more efficiently (right picture)

One more easy-to-understand case, the number of pull requests and active developers increases but the number of releases decreases, that would be a bad signal, so we should reduce the number of features at each release in order to deliver product faster.

Those are some examples of using metrics with efficiency. If we show more metrics on the dashboard, there will be more patterns, and bring more value to the engineering team.
Metrics can't tell a whole story
In my opinion, using metrics to evaluate the performance of an individual is a poor practice. For instance, at some point in time, that engineer is focusing on research tasks or writing documents, test cases, or busy to communicate with other teams. The work has no output at present but may have output in the future. In addition, engineers' performance also depends on other objective factors (working environment..etc), therefore hasty conclusions engineer's performance, which can lead to conflict between team members. A wisdom manager/leader should use metrics to start a conversation.
Management is all about context, metrics should be used as a starting point of a discussion
What's in the next phase?
There are still so many metrics under development. For example, we can get data from CI/CD tools to calculatefailed test rate, time for building docker image, deployment time… Or delivery time metric - Time from the feature (issue or ticket) was created until the release of the feature to the market.
One of the functions being developed is called the Grouping function. Basically, A team can handle many projects at the same time, each project may be implemented in many repositories (xxx_api, xxx_web, xxx_mobile). By grouping those repositories on only one dashboard, it will help project leader grasps the current development situation of project.
From day one, Fadil will try to help other teams more successfully by looking at engineering metrics.
Conclusion
What if there are 1000 repositories, 2000 repositories handled by 1000 engineers ? How engineering managers could catch up with all these project development ?
When your application has 10 users, there is no need to track the metric of application. But if your application has 1 million users, you start to care about latency, CPU, memory. Then your application grows to 100 million users, you actually want to track everything. The point is, as an application scales, we need to track more to understand how our application is working to make sure there is no bottleneck. I think that simple idea also can be applied to scale an organization.
The more we know about our organization, the better solution we can give.
--
マネーフォワードでは、エンジニアを募集しています。 ご応募お待ちしています。
【サイトのご案内】 ■マネーフォワード採用サイト ■Wantedly ■京都開発拠点
【プロダクトのご紹介】 ■お金の見える化サービス 『マネーフォワード ME』 iPhone,iPad Android
■ビジネス向けバックオフィス向け業務効率化ソリューション 『マネーフォワード クラウド』
■だれでも貯まって増える お金の体質改善サービス 『マネーフォワード おかねせんせい』