
こんにちは! マネーフォワードのCTO室マイクロサービス推進部でインターンをしている廣瀬です。 今月6月にメール取込というサービスをリリースしました(お知らせ)。 メール取込に関する概要や目的についての詳細はこちらのブログに記載されていますので、気になる方はご一読ください。
メール取込は、マネーフォワードの様々なプロダクトで、ユーザーに手入力を強いている点を解決することを主な目的としています。そこで、メール取込の価値向上のために解析可能な領収書メールの拡充を、インターン生主導で進めています。 今回は、できるだけ早く効率的に解析対象サービスを増やすことを目的としてインターンチームが取り組んでいることについて紹介します。
アーキテクチャ(メール解析)
まず、メール解析部分のアーキテクチャについて紹介します。 今回は、図中のDispatcherとParserに焦点を当てて説明します(詳細な処理の流れについてこちらを参照してください)
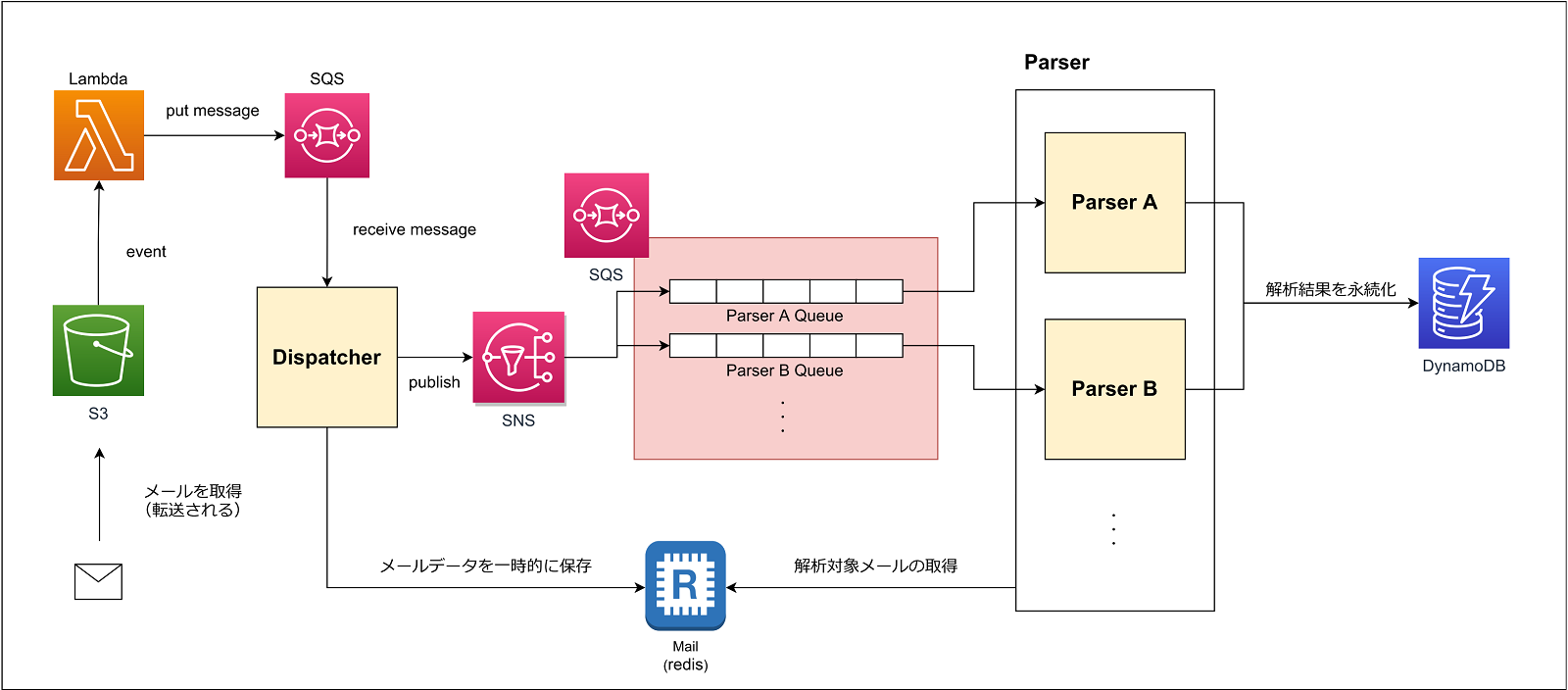
Dispatcher
受信したメールがどのサービスから提供されたのかを判定し、Parserに対してSNSを使用してメッセージを送信します。 また、同じメールを2回以上処理しないようにチェックを行い、メールを一時的なキャッシュ領域としてRedisに保存するような処理も含まれています。
Parser
領収書メール(本文や添付ファイルなど)を解析し、データとして保存するためのプロセスです。
具体的には次のような処理が実行されます。
- Dispatcherから送られたメッセージをSQSから受信
- 解析対象のメールであるかをフィルタリング
- 解析・データを抽出
- 必須項目が正しく抽出できているかを判定
- 解析後のデータをDynamoDBに永続化
解析対象サービスごとにプロセスを分けることで、スケーラビリティを備え、負荷分散を実現する他、特定のサービスの領収書解析に失敗した際に他のParserに影響が出ないようにしています。
領収書メールは、以下のような特徴があります。
- 送信元のサービスごとに記載内容や領収書の形式が異なる(例えば次の通り)
- HTML メールに領収書が記載されている場合
- plain text で領収書が記載されている場合
- PDF領収書が添付されている場合
- PDF領収書のダウンロードリンクがメールに記載されている場合
- 予期せずレイアウトが変更される可能性がある
メール取込を利用するサービスは、ここで抽出したデータを前提としてサービス固有のデータを作成します。間違った情報を抽出してしまうと、壮絶なデータパッチが発生し、時にはユーザにコミュニケーションを取らなければいけなくなる可能性があります。
このような背景から、メール取込では正確にデータを抽出することを最優先にしており、柔軟(曖昧)な実装は避けています。 そのため、機械学習などの技術を使わずに以下の方法を用いて領収書メールに対して、固定解析をしています。
- HTMLメールのスクレイピング、または文字列処理によるテキスト抽出
- PDF領収書の場合はテキストに変換した後に、文字列処理によるテキスト抽出
解析対象の領収書メールを量産化する方法について
現在、さらなるプロダクト価値向上のために解析対象サービスの拡充を進めていますが、共通の実装部分や同じような作業工程が必要であるという課題が多々あります。 そこで、解析対象サービス固有の実装(解析処理など)だけを意識すれば良いような仕組みを目指して、現在取り組んでいる領収書解析サービス量産化に対するアプローチ(主に2種)について紹介します。
- 実装量の削減
- 実装以外の工程の削減
1. 実装量の削減
新規のParserの開発者が書くコード量を減らすための取り組みです。
Parserにおいて、サービスごとに異なる部分はデータモデルの定義 + 以下の3つの処理になります。
- 解析結果の保存形式(領収書のデータモデル)の定義
- 解析対象のメールであるかをフィルタリングする処理
- 解析処理
- 解析結果のバリデーション処理
新規のParserの開発者の対応内容が、これらのサービス固有の処理とテストの実装だけになると、Parserの量産スピードが向上します。 そこで、Parser共通の実装コード・プログラムの雛形や、マイグレーションファイル、CIに関するconfigファイル、HCLによるデプロイに関する設定ファイルなどを自動生成するツールを開発しています。
2. 実装以外の工程の削減
解析対象サービスの拡充は、インターン生が主導しており、短期インターン生を積極的に受け入れています。 そこで、開発者のコード量を減らす以外にも、作業工程の属人化を防ぎ、新規のメンバーでも速やかに対応できる体制を整備することが重要だと考え、以下の取り組みを行っています。
ドキュメントの整備・拡充
主に、サービスの違いによる実装の個性をなくすことを意識してドキュメントを整備しています。
例えば、以下のようなドキュメントを整備しています。
- 領収書データモデルの設計方法や、よく使われるフィールド名・レビュー観点
- 解析処理でよく使うコードと実装の仕方
- 抽出結果のバリデーション処理に関するレビュー観点
個性をなくすことで、新規メンバーでも対応しやすくなり、レビュー対応のスピードも早くなります。 また、領収書の形式が変更された際の速やかな修正対応も実現可能になります。
issue起票の自動化、PR作成、マージの自動化
解析対象サービスを追加するためのリリースまでの工程は共通であるため、Github Actionsなどを使用してissueを自動で起票するようにしています。
また、設定ファイルなど、ツールによって生成されたコードを適用するだけで完了するタスクもいくつか存在します。 これらの、ツールによって生成したコードのレビューは不要とすることで、量産化のスピードをさらに向上させています(生成されたコードに対して、人の手を入れた場合は除きます)。
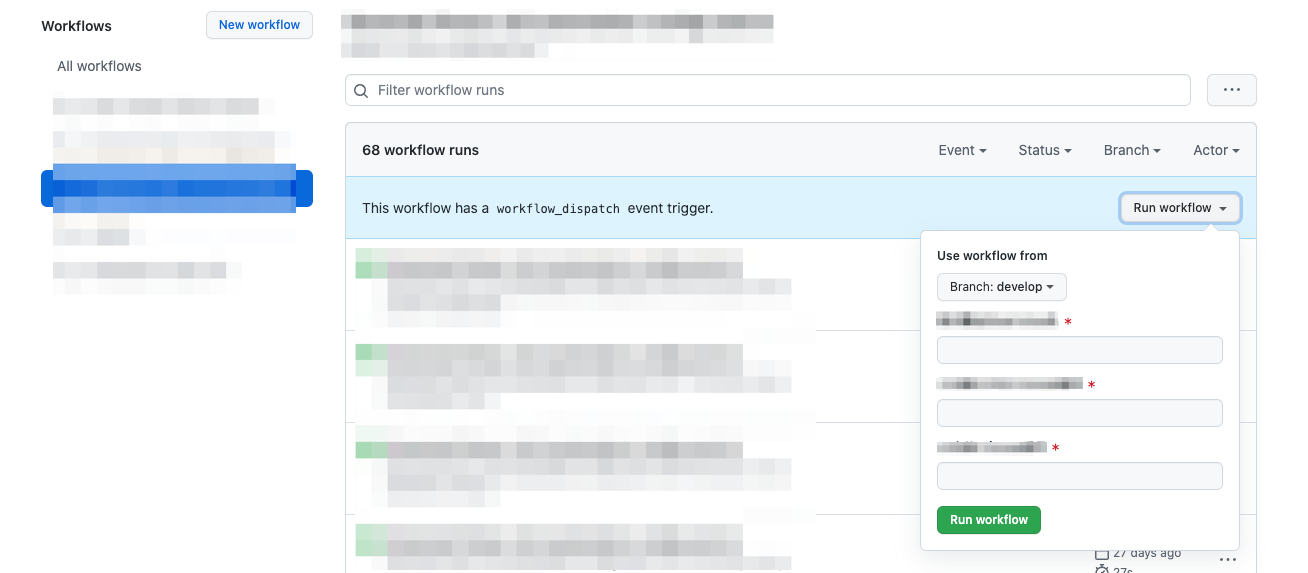
人の手が入っていないことを担保するために、Github Actions の workflow_dispatch event によって下記を実行できるようにしています。
- コードの生成
- 生成後に自動でPRを作成
- PRを自動でマージ
workflow_dispatchイベントは、GithubのActionタブから手動でパラメータを使用して実行することができます。
量産化に関する取り組みの結果と現状の課題
これまで、新メンバーが1つ領収書解析サービスをリリースするのに10日程度かかっていましたが、現在では半分の5日程度のスピードで実現できるようになりました(慣れたメンバーだと2-3日)。
一方で、以下のような課題もあるため、解析サービスのリリースの速度をさらに向上させる取り組みを日々行っています。
- 特にテストコードなど、まだまだ開発者が書くコードの中で一部自動生成ができるものがある
- 複数人が並列で解析サービス追加を行った際、コンフリクトが大量発生する設定ファイルがいくつか存在する
- 実際に提供されたメールの中から、個人情報をマスクし、テストデータを作成するのに工数がかかる
まとめ
今回は、メール取込で解析可能な領収書メールの拡充のために行っている取り組みについて紹介しました。 できるだけ早く効率的に解析対象サービスを増やすことを目的として、実装量の削減や、実装以外のドキュメント整備・レビュー自動化などの体制を整えています。
メール取込は初期リリースを終えた段階で、まだまだ改善すべき課題の多いプロダクトですが、今回紹介した量産化の活動によって、今後メール取込およびメール取込を利用するサービスの価値をさらに向上できると考えています。 加えて、インターン生が主導していることもあり、インターン生でありながらとても大きな裁量で活動させてもらっています。 最後に、このような環境で主体的に課題を見つけ、一緒に向き合い、解決していけるメンバーを募集しています。ご興味を持っていただけた方はぜひご応募ください!
CTO室エンジニアの募集: https://hrmos.co/pages/moneyforward/jobs/0004187
マネーフォワードでは、エンジニアを募集しています。 ご応募お待ちしています。
【サイトのご案内】 ■マネーフォワード採用サイト ■Wantedly ■京都開発拠点
【プロダクトのご紹介】 ■お金の見える化サービス 『マネーフォワード ME』 iPhone,iPad Android
■ビジネス向けバックオフィス向け業務効率化ソリューション 『マネーフォワード クラウド』
■だれでも貯まって増える お金の体質改善サービス 『マネーフォワード おかねせんせい』