
こんにちは!マネーフォワードのHR領域でQAエンジニアをしている森田です。私たちのチームでは、「エンジニア自身が品質を担保してリリースできる組織」を目指し、施策として4本柱を掲げて日々活動しています。その1つが「品質の可視化」です。
品質の可視化の第一弾として、不具合の可視化に着目し、不具合分析をおこなっています。施策を開始してから、気づけば1年以上も経っていました(早い)。
前回は不具合分析の運用の導入についてお話しました。
今回は、具体的にどんな切り口で分析しているのか、分析したデータをどのように開発活動に還元しているのかについてお話します。
不具合分析で試行錯誤している方に、少しでも参考になる点がありましたら、とっても嬉しいです!
なぜ不具合分析をしたいのか
前回のブログで記載した内容と重複していますが、大事なことなので、再掲します。
HR全体で、不具合件数を可視化することによって、
- まずは、現状の不具合件数を把握したい(現状が分からないと議論もできない)
- 次に、不具合の件数を減らしていくための施策を考えて実施する。
- そして、不安や不満の要素になるものをゼロに近づけていく
集計している不具合の範囲
さあ、不具合データを集めよう!
そう思った時に最初にぶつかった壁が、どこまでの範囲の不具合を集計するかです。
まずは社外からのお問合せ起因の不具合発覚を減らしたいという思いから、以下のように決めましえた。
- 実装後の機能テスト(結合テスト、統合テストフェーズ)や試食(リリース前にCSさんやセールスさんが機能を触るイベント)で見つかった不具合
- ユーザーさんからのお問い合わせ、開発チーム(QAエンジニア含む)外からの社内お問い合わせ起因で調査を開始し、意図とした挙動と異なっていることが発覚したもの
- 仕様バグ(不便だけれど、意図した挙動)の場合は不具合としてカウントしない
- Rollbarなどのモニタリングシステムで発見されたエラー
なお、実装中(ユニットテスト含む)で見つかった不具合はissueとして起票しなくて良いとしました。理由は、どこまでの範囲を起票するのか(実装ミス・実装漏れ、仕様の検討漏れなど)を線引きするのが難しい&実装中に見つけられたのは良いこと(それ以降のフェーズに比べると品質コストも低い)と考えたからです。
部で定義している不具合ランク
致命的な不具合の数を減らしたい!
致命的な不具合とは何かの共通認識を持つために、不具合ランクを定めました。

不具合分析の運用の概要
チームによって運用方法が異なるところもありますが、大体以下の流れで運用しています。
- (随時)開発エンジニアは、不具合issue/チケットにラベルをつける
- (日次)GASで、不具合issue/チケット情報がスプレッドシートに出力される
- (日次)Looker Studio(旧Googleデータポータル)に、不具合件数などが反映される
- (週次)開発エンジニア+QAエンジニアで、不具合の分類づけ会を実施
- (月次〜四半期毎)QAエンジニア主体で、不具合の傾向を分析
それぞれのやりたいことと実現方法
1.(随時)開発エンジニアは、不具合issue/チケットにラベルをつける
やりたいこと
- 分析対象のissueを区別し、集計しやすくする
実現方法
- 調査を経て不具合と発覚したタイミング、あるいは、不具合修正が終わったタイミングでGitHubのissueに不具合ラベルをつける

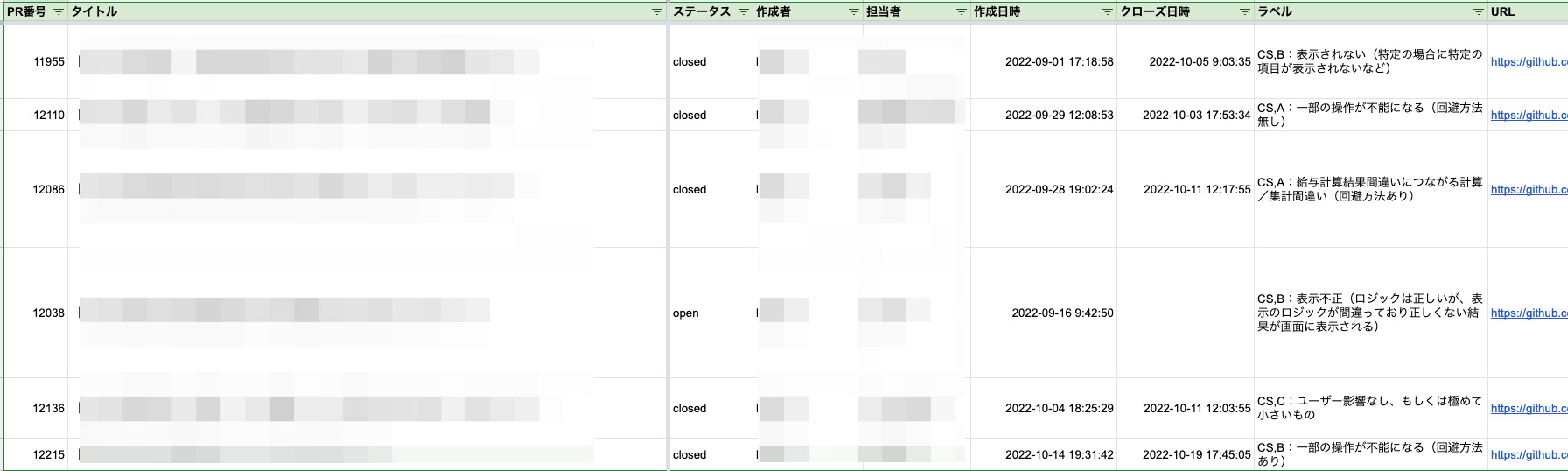
2.(日次)GASで、不具合issue/チケット情報がスプレッドシートに出力される
やりたいこと
- 集計対象の不具合リストを簡単に作成する
実現方法
- Github → スプレッドシート
- Asana → スプレッドシート
- JIRA → スプレッドシート
出力結果
3.(日次)Looker Studio(旧Googleデータポータル)に、不具合件数などが反映される
やりたいこと
- いつでも最新の集計結果を閲覧できるようにする
プロダクト別の件数推移

不具合のうち、ユーザーさんへのインパクトが高いものを「emergency」と部内で読んでいます。emergency件数を減らしていくことによって、より安心安全なサービスの提供を目指しています。
4.(週次)開発エンジニア+QAエンジニアで、不具合の分類づけ会を実施
やりたいこと
- 分析が行えるよう、収集した不具合情報に分析したい切り口での情報を付加する
- どうしたら防げたか、今後防ぐにはどうしたら良いか議論する
- Next Actionを明らかにし、対策を忘れないようにする
分類の切り口
- 不具合ランク、不具合分類(上で紹介したもの)
- 対象機能
- 検出したフェーズ
- 検出すべきだったテスト
- 原因分類
他にも、チームごとに必要に応じて追加している項目もあります。

参加者
- 開発エンジニア
- 全開発エンジニアが参加しているチームもあれば、数名代表して参加しているチームもある
- QAエンジニア
- 不具合の可視化PJ担当のQAエンジニア
- プロダクト担当のQAエンジニア
- チームによっては、PdMやグループリーダーも参加
会の流れとしては、
まず、不具合の内容を、実装担当者が説明します。
まだ不具合の原因がわかっていない調査中のものは、次回に回しても構いません(原因分類を埋められないので)。また、件数が多くてMTG内(30分)で話が終わらなさそうな場合は、不具合ランクの高いものから取り上げていきます(よりインパクトの大きい不具合に時間を割く)。
次に、それぞれの不具合の分析項目(対象機能、検出したフェーズ、検出すべきだったテスト、原因分類)を埋めていきます。
ファシリの方(開発エンジニア)が埋めていきます。分類や原因について自信のない箇所があれば他の参加者に質問を投げかけながら進めていきます。参加者(開発エンジニア、QA)も気になる箇所があったら質問や議論をします。
最後に、今後の対策を議論します。
対策の要不要を判断し、要と判断した不具合に対して、再発防止策を議論します。今回の不具合が再発しないと、同様の事象が他の機能でも発生しない、の2つの視点で考えることが大事だと考えています。
5.(月次〜四半期毎)QAエンジニア主体で、不具合の傾向を分析
やりたいこと
- 不具合情報を俯瞰的に見て、重点をおくべき改善ポイントを明らかにする
- 傾向に変化がないか、ウォッチする
プロダクト毎 対象機能別不具合件数

横軸が対象機能、縦軸が件数です。より着目したい不具合ランク(S,Aランク)を抽出し、どの機能に不具合が集中しているかを可視化しました。
どのプロダクトでも、メイン機能、多くのユーザーが利用する機能での不具合数が多いことが分かりました。

棒グラフが機能ごとの不具合件数、折れ線グラフが不具合全体に対する、機能ごとの発生件数の累積比率です。
この機能とこの機能の合計で、プロダクト全体の6割の不具合を占めているね、ということがわかります。上記のプロダクトでは、一番左の一機能で全体の2割の不具合を占めていることが分かりますね。
混入したフェーズ 累計との比較

左が累計、右が今期のグラフです。傾向はプロダクト毎に異なっています。上記プロダクトの場合は、実装時の混入が半数を超えています。
データを蓄積してから1年分がたまったタイミングで累計との比較をしましたが、傾向は変わっていませんでした。
検出すべきだったテスト
 左が累計、右が今期のグラフになります。青色specはRSpecを指し、オレンジの単体テストはRSpec以外の単体テスト(Jestなど)を指しています。
左が累計、右が今期のグラフになります。青色specはRSpecを指し、オレンジの単体テストはRSpec以外の単体テスト(Jestなど)を指しています。
傾向はプロダクト毎に異なっていて、上記プロダクトの場合はRSpecで検出すべきだった件数が半数を超えていることがわかります。
会の流れとしては、事前にQAエンジニアが分析し用意したレポートを利用し、開発エンジニア、グループリーダー向けに分析から見えてきたことを報告します。
QAエンジニア側では議論ポイント(特に減らしていきたい不具合の特徴)を提示し、みんなで議論し、Next Actionをとるものを決めます。
具体的な成果
クラウド勤怠の開発エンジニアさんより(引用元:【クラウド勤怠】QAがチームに入ったことで変化したソフトウェア品質向上に向けた活動>不具合分析会の開催)
正直な所、始めてから1\~2ヶ月目はこんなに不具合の詳細部分までの議論をして果たして意味があるのだろうか?といった気持ちで懐疑的でした。しかし3ヶ月目以降になると不具合が起こりやすい画面や不具合の傾向などが少しずつ見えてくるようになり、エンジニア側でも開発をするときに「このあたりはバグが起こりやすいから、もう少し詳しくコードを読んでみよう」「このあたりはリグレッションテストをした方が良いかもしれない」といった行動が観測できるようになり、確実にエンジニア間で蓄積した不具合のナレッジが活用できるようになりました。
(ちなみに、意味があるのかと言われた際には、半年は様子を見させてほしいと話をして継続させてもらいました)
別のとあるプロダクトでは...不具合分析から品質改善のアクションにつながりました。
- 不具合の傾向を分析したところ、実装時の不具合混入、RSpec(単体テスト)で防ぐべき不具合が半数を占めていることがわかった
- 単体テスト周りの課題や困っていることをヒアリング・議論し、単体テストの実装指針をまとめるのが良いということが決まった
- 後日、開発エンジニア主体で資料をまとめていただいた
苦労したこと
チーム毎に利用しているツールが異なるので、俯瞰して全体像をみることの難しさ
こちらからもわかる通り、チケットの管理方法が、チームによって異なっています。これまで、スモールチームでより高速に開発業務を回すことを優先するために、使うツールは各チームで決めていました。組織が拡大していく中で、HR開発全体で俯瞰的に不具合情報や傾向を見ようとする際に、手間がかかってしまっています。
分析のその先へ。品質改善アクションに繋げることの難しさ
半年、1年と経ったところで、俯瞰的に不具合の傾向が見えるようになり、プロセスの弱みが見え始めました。前年比較もできるようになり、プロダクト・プロセスの弱い箇所が変わっている箇所/変わっていない箇所も見えてきました。
一方で、品質改善施策が実行されないという課題が浮き彫りになり、明確な解決策はまだくっきりは見えていないのが現状です。
次にやりたいこと
改めて活動を振り返ってみると、不具合の中身を眺める時間を確保できているのはとても良いことだなと思いました!
不具合の知見を周りの人と共有できますし、同じことを発生させないためにはどう仕組みで解決できるかを考える時間にもなっています。
今後は、蓄積した不具合データ=資産を品質改善アクションの実施に確実に繋げていくことに挑戦していきたいです。数ヶ月のブランクはできてしまいますが、半年毎の目標設定時にこれまでの議論で出てきた品質改善アクションを行うのか否かを話し合うもの良さそうと考えています。
(おまけ)品質施策を進めるために挑戦したこと
不具合分析 →品質改善アクションに繋げることには苦労していますが、開発チームを巻き込んだ品質施策の実行では上手くいったこともありました。
挑戦したことは、各開発チームのリーダーと話をして、開発チームの目標に品質施策を入れてもらう&品質担当をアサインしてもらうようにしたことです。
トライアル運用を開始しても、継続・定着しなければ意味がありません。(もちろん、やっていることに意義があることが前提で、問題箇所があれば随時改善・アップデートしていきます)
1から10まですべてQAの方でやるのでは、やりたいこと(ユーザーの不安や不満の要素をゼロに近づけていくためには、まずは不具合を可視化することが必要)は開発チームになかなか浸透しません。
また、その開発チームでどのような運用にするのが一番良いかは、その開発チームの皆さんが一番わかっています。
そこで、開発チームのリーダーに相談して、開発チームの中で品質担当の方をアサインしてもらいました。
(引用元:マネーフォワードHR領域プロダクトでの不具合分析の取り組み(導入編)>運用定着のためには、開発チームがオーナーシップを持てるようにするのも結構大事)
これを実践するためには、他のチームより1ヶ月くらい前倒しで自チーム(QAチーム)の目標を考える必要があります。
半年毎(開発チームが目標設定する1ヶ月くらい前)に、その半年の品質施策の振り返りと次の半年の目指す方向性について各チームと話し合っています。
- 予定していた品質施策が実行できたか
- 品質施策を実行した結果、どのような良いことがあったか
- さらに見えてきた課題は何か
- 施策とは関係なしに、最近品質・テストの文脈で不安なことはあるか
この進め方はうまくいっているので、継続して行っていきたいです。
マネーフォワードでは、エンジニアを募集しています。 ご応募お待ちしています。
【会社情報】 ■Wantedly ■株式会社マネーフォワード ■福岡開発拠点 ■関西開発拠点(大阪/京都)
【SNS】 ■マネーフォワード公式note ■Twitter - 【公式】マネーフォワード ■Twitter - Money Forward Developers ■connpass - マネーフォワード ■YouTube - Money Forward Developers