
みなさん、こんにちは! マネーフォワードでビジネス分析とかしてる人、酒井です。
現在、私は定量分析を民主化すべく、BigQueryに各種集計に使うテーブルを集めたデータウェアハウス(以下、DWH)を構築しています。
ただ集めるだけでなく、テーブル間のリレーションやフィールドの意味など、専門的な知識を上手に隠蔽したサマリテーブルを作ることで、データ分析の裾野が広がることを期待しています。
その中、特に経営分析や戦略策定において「売上」をいかに解像度高く確認できるかが重要です。
今回のDWHも、事業部・プロダクト・チーム・Stock/Flowなど、あらゆる断面で切っても同じ定義の「売上」が出たサマリテーブルを作ることが求められています。 (この事と現状のカオスさからこのプロジェクト名をフラクタルと命名しました)
一方で、経理処理は財務諸表を作ることが目的なので高解像度で売上を集計しておらず、また処理自体もExcelによる手作業であるためリードタイムがあり速報性が落ちてしまうなど、現状の経理プロセスには経営分析上の問題がありました。
結果的に、表題のとおり経理処理をBigQueryのSQLで実装する必要が出たわけです。
経理処理を理解する
今回、ご紹介する経理処理は、マネーフォワードクラウド給与 をご提供している方法のひとつである、チケットの処理です。
チケットには、下記のような特性があります。
- 1枚使うと、1人分の給与処理ができる
- チケットは予めお客様に何十~何千枚という単位で納品している
- 販売/納品時点では売上は立たず、実際に利用された時点で売上が立つ (発生主義)
- チケットの単価は”利用されてないチケットの平均単価”が採用される (平均法)
基本的にはシンプルな処理ではありますが、特に4番が曲者なので、例を出してご説明します。
【N月】 月初に使われてないチケットを調べると、単価100円のチケットが10枚あった。(=前受収益が1,000円) 月末までに、使われたチケットの枚数は5枚だった。 → 100円×5枚=500円の売上。
【N+1月】 月初に使われてないチケットを調べると、単価100円のチケットが5枚あった。(=前受収益が500円) 月末までに、単価200円のチケットを15枚売った。(=前受収益が3,500円) 月末までに、使われたチケットの枚数は5枚だった。 →(100円×5枚+200円×15枚)/(5枚+15枚)=175円が平均単価なので、売上は875円。
例をみて、なんとなく何が変数になるかおわかりでしょうか? 一つの答えは下記のとおりです。
- 各月の新規販売枚数
- 各月の新規前受収益
- 各月の消費枚数
2については=枚数×単価なので単価といっても良いのですが、定式化の都合で前受収益とさせてください。
(前受収益とは、お金はもらっているけどまだ売上と見做せないもの、という勘定科目です)
定式化してみる
どのように処理を書くものか悩みますが、ここまで算数的な問題であれば一度算数にしてみたいと思います。 「今までの合計販売枚数」みたいな概念が出るということはΣみたいな、アレルギー性のある記号が発生しそうな予感がするので、簡単のために一度Excelで表現してみます。
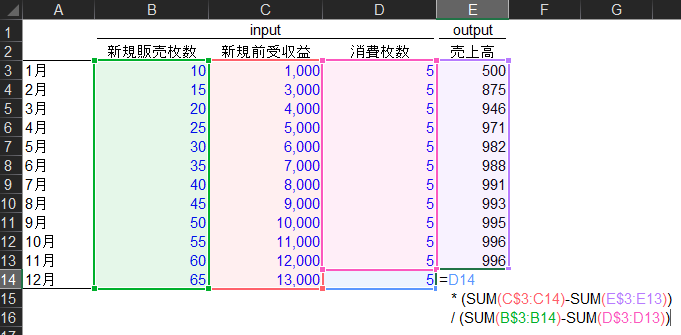
どうでしょうか?少しは視覚的に理解できましたか? D14が今月の消費量[枚]で、それ以降が単価[円/枚]です。 2行目の(SUM()-SUM())で残っている前受金を計算しています。 3行目の(SUM()-SUM())は残っているチケットの枚数を計算しています。
さて、もちろんこの理解があれば十分に実装できるのですが、あえて一度数式に落としましょう。 案の定、アレルゲンな数式が出てきました。
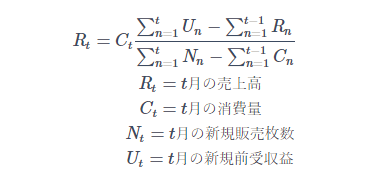
ここで気づけるのは以下の2つです。
- 売上高を計算しているのに、右辺にも当該月以前の売上高がある
→ 再帰を使う実装になりそう - Σを計算しているので毎月の集計に、当該月以前のデータが全部いる
→ 配列を渡す必要がありそう
BigQueryで再帰を実装可能か確認する
再帰なんて、それこそ大学の授業でフラクタル図形書いてみよう!という課題に取り組まされて以来です。 そもそもSQLで再帰って実装できるのか?ということから確認しました。
SQLで再帰を書く方法には、下記の2つがあります。
- 再帰SQLを書く
- UDF(ユーザー定義関数を使う)
現在BigQueryでは再帰SQLをサポートしていませんので、今回はUDFを書くことにしました。
UDFは、SQL内で呼び出せる関数を独自に作成するという機能で、BigQueryの場合はJavascriptで定義することが可能です。とはいえ、本当にBigQueryのUDFで再帰を実装できるのか不安だったので、まずフィボナッチ数の吐き出しを実装できるか確認しました。下記が典型的なコードで、fib()内でfib()が呼ばれているのがわかります。
CREATE TEMPORARY FUNCTION fibonacci(
tail INT64 -- 知りたいフィボナッチ数列の番目
)
RETURNS INT64
LANGUAGE js AS """
function fib(n) {
return n < 2 ? n : fib(n - 2) + fib(n - 1);
}
return fib(tail);
""";
select fibonacci(10) ;
>> 55
調べるとfibonacci(10)は確かに55なので問題なくBQで再帰を使えそうです。
BigQueryで「配列を引数に配列を返すUDF」を実装できるか確認する
こちらも結論としては可能なのですが、そもそもなぜこの確認が必要か考えます。 下記再掲ですが、いたるところにΣがあり、t=1からt=直近月までの各変数の配列を引数で渡す必要があることに気づくことができます。

おそらく、今回の処理の引数は
CREATE TEMPORARY FUNCTION pa_ticket_revenue( 新規契約高 ARRAY<INT64> , 新規チケット販売量 ARRAY<INT64> , チケット消費量 ARRAY<INT64> )
といった渡し方になるはずです。
また、引数に知りたい月を与えることで、その月の売上高だけを返すこともできますが、少々計算量がかさみます。 というのも、N月の売上を計算する際にはN-1月以前の売上も全て計算する、すなわち最終月の計算には、それ以前の全ての売上計算がされるので、このUDFの呼び出しは1回にして全月の結果を配列で返してくれるのがエコになります。
下記が「配列を引数に配列を返すUDF」の実装が可能だということを証明するクエリです。
配列化とunnestを何度かやっているのでSQL部分が長いですが、ARRAYを引数にARRAY返すUDFがきちんと実装可能だというのが肝要です。
CREATE TEMPORARY FUNCTION sigma(
arr ARRAY<INT64>
)
RETURNS ARRAY<INT64>
LANGUAGE js AS """
function sigma(arr){
return arr.reduce(function(prev, current, i, arr) {
return parseInt(prev) + parseInt(current);
});
}
var result = [];
for(var i=0; i<arr.length; i++){
result.push(sigma(arr.slice(0, i+1)));
}
return result;
""";
-- 連番が入ってるだけのテーブルを作る。ほんとは冗長なんだけど本番の実情に合わせて
with numbers as (
SELECT n FROM UNNEST(GENERATE_ARRAY(1, 10)) AS n ORDER BY n
)
-- 1行1列のarrayが入ったテーブル
, array_numbers as (
select array(select * from numbers) as arr
)
, array_result as (
select sigma(arr) as result from array_numbers
)
select offset, element
from array_result
cross join unnest(array_result.result) as element
WITH OFFSET AS offset
;
経理処理をUDFに落として、BigQueryで実装する
ここまでの定式化と検証を組み合わせると、下記の通り経理処理を実装できました。
(注:僕には変数をvarで初期化する悪癖があります…。JSはいつもGASで使うのですが、どうもGASにおけるconstやletの挙動が怪しい?僕が理解できていない?んですよね…)
CREATE TEMPORARY FUNCTION calc_revenue(
sales ARRAY<INT64>
, salesVolume ARRAY<INT64>
, consumption ARRAY<INT64>
)
RETURNS ARRAY<INT64>
LANGUAGE js AS """
function sigma(arr){
try{
return arr.reduce(function(prev, current, i, arr) {
return parseInt(prev) + parseInt(current);
});
}catch(e){
return 0;
}
}
function revenue(sales, salesVolume, consumption){
var len = sales.length;
if(len == 0){
return 0;
}else{
var cumulativeSales = 0;
for(var i=0; i<len; i++){
cumulativeSales += revenue(
sales.slice(0, i)
, salesVolume.slice(0, i)
, consumption.slice(0, i)
);
}
return(
consumption[len-1]
* (sigma(sales) - cumulativeSales)
/ (sigma(salesVolume) - sigma(consumption.slice(0, len-1)))
);
}
}
var result = [];
for(var i=0; i<sales.length; i++){
result.push(
revenue(
sales.slice(0, i+1)
, salesVolume.slice(0, i+1)
, consumption.slice(0, i+1)
)
);
}
return result;
""";
-- 1行1列のarrayが入ったテーブル
with pa_raw_array as (
select
array(select sales from `project.data-set.pa_raw`) as sales
, array(select sales_volume from `project.data-set.pa_raw`) as sales_volume
, array(select consumption from `project.data-set.pa_raw`) as consumption
)
, revenue_array as (
select calc_revenue(sales, sales_volume, consumption) as result
from pa_raw_array
)
select offset, revenue
from revenue_array
cross join unnest(revenue_array.result) as revenue
WITH OFFSET AS offset
;
さて、この実装は正しい計算をするのですが、大きな問題がありました。 このスクリプトのオーダーを調べるとO(2n)と完全にだめなアルゴリズムで、実行したとしても地球文明の崩壊のほうが早そうです。 (チケット販売開始から50ヶ月程度立っているのですが、250≒1000兆です)
メモ化を使ってオーダーを削減する
こういうときはメモ化です。 今回、あくまで売上の計算は高々50ヶ月分しかないのに、一回計算した月の売上を何億何兆回といままでは繰り返し計算していました。 一度計算したものをどこかに記録しておけば、この無駄な計算を削減できます。 (と、それっぽく語っていますが、新卒エンジニアに教えてもらいました。優しい世界。)
どのスコープにメモの配列置くかちょっと混乱しながらも、下記の通り書くと期待通りの挙動をしました。 O(2n)がO(n)と線形になり、実行時間は2秒程度になりました。極めてハッピーです。
CREATE TEMPORARY FUNCTION calc_revenue(
sales ARRAY<INT64>
, salesVolume ARRAY<INT64>
, consumption ARRAY<INT64>
)
RETURNS ARRAY<INT64>
LANGUAGE js AS """
function sigma(arr){
try{
return arr.reduce(function(prev, current, i, arr) {
return parseInt(prev) + parseInt(current);
});
}catch(e){
return 0;
}
}
function revenue(sales, salesVolume, consumption){
var len = sales.length;
var memoization_result = memo[len];
if(typeof memoization_result == 'number'){
return memoization_result;
}else{
var cumulativeSales = 0;
for(var i=0; i<len; i++){
cumulativeSales += revenue(
sales.slice(0, i)
, salesVolume.slice(0, i)
, consumption.slice(0, i)
);
}
memo[len] = (consumption[len-1]
* (sigma(sales) - cumulativeSales)
/ (sigma(salesVolume) - sigma(consumption.slice(0, len-1)))
);
return memo[len];
}
}
var result = [];
var memo = [0]; //lenが0、すなわち販売前のrevenueが0であるため
for(var i=0; i<sales.length; i++){
result.push(
revenue(
sales.slice(0, i+1)
, salesVolume.slice(0, i+1)
, consumption.slice(0, i+1)
)
);
}
return result;
""";
-- 1行1列のarrayが入ったテーブル
with pa_raw_array as (
select
array(select sales from `project.data-set.pa_raw`) as sales
, array(select sales_volume from `project.data-set.pa_raw`) as sales_volume
, array(select consumption from `project.data-set.pa_raw`) as consumption
)
, revenue_array as (
select calc_revenue(sales, sales_volume, consumption) as result
from pa_raw_array
)
select offset, revenue
from revenue_array
cross join unnest(revenue_array.result) as revenue
WITH OFFSET AS offset
;
初期値であるmemo = [0]は、突っ込むデータの列数が0の場合のresultです。
一般的なメモ化同様、このmemoに過去出したことのある結果を格納しておき、結果がある場合はそれ以上revenue()を呼び出さず、memo [hoge]をreturnしています。
まとめ
再帰計算が必要なとき、多くの場合はスプレッドシートの世界に行くほうが簡単ではあります。 一方で、処理をSQLで行えたほうがプロセスとしてエレガントで、前後の処理に対しボトルネック化を防ぐ事ができます。
また、数式は多くの人にとってアレルゲンですが、頭を整理する一つのツール/言語として有用なので、ビジネスロジックの実装をする際には積極的に書いてみてはいかがでしょうか。 どうしても苦手な方であれば、スプレッドシートで実装してみて、右脳的に解釈するのもおすすめです。
なお、今回はBigQueryを採用したため再帰計算にUDFを使っていますが、環境さえあれば標準的な機能(再帰SQL)で実装しきるのが良いのかもしれません。 ただし、ちょっと調べた限りだと、再帰SQLのメモ化実装例が出てこないので、オーダーがスケールしちゃいそうなときは注意してください。
最後に
マネーフォワードでは、
- コードも書けるビジネス職
- ビジネスロジックのわかるエンジニア職
- そもそも、ビジネス職とかエンジニア職とか区別する意味わかんねえ
という方を募集しています! (実際にマネーフォワード開発合宿にも、僕のようないわゆる非エンジニア職が多数参加します)
奮ってご応募ください
【採用サイト】 ■マネーフォワード採用サイト ■Wantedly | マネーフォワード
【マネーフォワードのプロダクト】 ■自動家計簿・資産管理サービス『マネーフォワード ME』 iPhone,iPad Android
■ビジネス向けクラウドサービス『マネーフォワードクラウドシリーズ』 ・バックオフィス業務を効率化『マネーフォワードクラウド』 ・会計ソフト『マネーフォワードクラウド会計』 ・確定申告ソフト『マネーフォワードクラウド確定申告』 ・請求書管理ソフト『マネーフォワードクラウド請求書』 ・給与計算ソフト『マネーフォワードクラウド給与』 ・経費精算ソフト『マネーフォワードクラウド経費』 ・マイナンバー管理ソフト『マネーフォワードクラウドマイナンバー』 ・資金調達サービス『マネーフォワードクラウド資金調達』
■「しら」ずにお金が「たま」る 人生を楽しむ貯金アプリ『しらたま』 iPhone,iPad
■おトクが飛び出すクーポンアプリ『tock pop トックポップ』
■金融商品の比較・申し込みサイト『Money Forward Mall』
■本業に集中できる新しいオンライン融資サービス『Money Forward BizAccel(マネーフォワード ビズアクセル)』